Chance News 81: Difference between revisions
| Line 146: | Line 146: | ||
</blockquote> | </blockquote> | ||
Marilyn's approach amounts to using so-called "natural frequencies" to avoid all the fractions. Gerd Gigerenzer, in [http://www.statlit.org/Gigerenzer.htm numerous | Marilyn's approach amounts to using so-called "natural frequencies" to avoid all the fractions. The corresponding probability calculation would be | ||
<center> | |||
<math>.25+(.75)(.25)+(.75^2)(.25)+(.75^3)(.25) = .6836</math> | |||
</center> | |||
Gerd Gigerenzer, in [http://www.statlit.org/Gigerenzer.htm numerous publications over the years], has advocated natural frequencies as a more transparent way to present probability arguments for the lay person. See | |||
Steven Strogatz's 2010 article [http://www.causeweb.org/wiki/chance/index.php/Chance_News_63#Demystifying_conditional_probability.3F Chances are] (from his excellent [http://topics.nytimes.com/top/opinion/series/steven_strogatz_on_the_elements_of_math/index.html Elements of Math] series for the ''New York Times''), where he discusses Gigenzer's book ''Calculated Risks''. One of the examples discussed there uses the natural frequency approach to illuminate the false positive problem in the context of breast cancer screening. | Steven Strogatz's 2010 article [http://www.causeweb.org/wiki/chance/index.php/Chance_News_63#Demystifying_conditional_probability.3F Chances are] (from his excellent [http://topics.nytimes.com/top/opinion/series/steven_strogatz_on_the_elements_of_math/index.html Elements of Math] series for the ''New York Times''), where he discusses Gigenzer's book ''Calculated Risks''. One of the examples discussed there uses the natural frequency approach to illuminate the false positive problem in the context of breast cancer screening. | ||
Revision as of 01:20, 15 February 2012
January 18, 2012 to February 13, 2012
Quotations
Eminence based medicine—The more senior the colleague, the less importance he or she placed on the need for anything as mundane as evidence. Experience, it seems, is worth any amount of evidence. These colleagues have a touching faith in clinical experience, which has been defined as “making the same mistakes with increasing confidence over an impressive number of years.” The eminent physician's white hair and balding pate are called the “halo” effect.
from Seven alternatives to evidence based medicine, British Medical Journal, 18 December 1999
Submitted by Paul Alper
"Alternative therapists don't kill many people, but they do make a great teaching tool for the basics of evidence-based medicine, because their efforts to distort science are so extreme."
Ben Goldacre, in What eight years of writing the Bad Science column have taught me, Guardian, 4 November 2011
Submitted by Bill Peterson
(Note: With regard to last two quotations, see Andrew Gelman's recent blog post on Evidence Based Medicine, which links to slides from an overview lecture that was presented at the 2011 Joint Statistical Meetings.)
"Of course, from the quasi-experimental perspective, just as from that of physical science methodology, it is obvious that moving out into the real world increases the number of plausible rival hypotheses. Experiments move to quasi-experiments and on into queasy experiments, all too easily."
Donald T. Campbell, in Methodology and Epistemology for Social Science: Selected Papers, page 322.
Submitted by Steve Simon
"Statisticians are a curious lot: when given a vertical set of numbers, they like to look sideways." (p. 146)
"Since statisticians are trained to think rare is impossible, they do not fear flying, and they do not play lotteries." (p. 179)
Kaiser Fung, in Numbers Rule Your World: The Hidden Influence of Probability And Statistics On Everything You Do
Submitted by Paul Alper
(Note: Kaiser writes two blogs of interest to Chance News readers: Junk Charts and Numbers Rule Your World)
Forsooth
“.... In a study involving 11,000 patients hospitalized for nearly four dozen ailments, researchers found that, across the board, women reported suffering pain more acutely than men did. …. The patients were asked to self-report their pain – in most cases to a female nurse.”
TIME, February 6, 2012, p. 14
See also Sex differences in reported pain across 11,000 patients captured in electronic medical records, Journal of Pain, January 2012. (There is a fee to access the full text.)
Submitted by Margaret Cibes
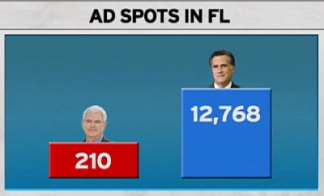
A Forsooth Graphic
http://community.middlebury.edu/~wpeterso/Chance_News/images/CN81_FL_2012.png
{kind=link}
"Why even bother making a graph? [Laughing] I'm sorry. It looks like that is what, a third of 12,000? Not to scale….. The worst bar graph in the history of cable news.”
Submitted by Margaret Cibes
Vote Early, Vote Often
From a Washington Post News Alert dated Tuesday, January 31, 2012 8:08:06 PM:
"Mitt Romney wins Florida primary
"Former Massachusetts governor Mitt Romney won the Florida primary as voting finished Tuesday evening, a victory expected to cement his status as the Republican front-runner.
"Voters picked Romney over former House speaker Newt Gingrich as the best positioned to take on President Obama in November.
"With just under 40 percent of the precincts reporting, Romney was leading with 78 percent of the vote, followed by Gingrich with 31 percent, Rick Santorum with 13 percent and Ron Paul with 7 percent."
The Post issued a correction about twenty minutes later.
Submitted by Marc Hurwitz, with thanks to Robert Haemer
Question of significance
Ultrasounds detect cancers that mammograms missed, study finds
by William Weir, The Hartford Courant, January 13, 2012
A 2009 CT law requires that “all mammogram reports include the patients' breast density information, and that women with greater than 50 percent density be recommended for additional ultrasound testing.” CT is apparently the first state to pass such a law.
For the period October 2009 to 2010, a University of Connecticut Hospital radiologist collected data on more than 70,000 cases, of which about 8,600 involved ultrasound screenings, and she found that the screenings “detected 3.25 cancers per 1,000 women that otherwise would have been overlooked.”
"When you think about it, we find four or five per thousand breast cancers in an overall screening population. So, then you add that extra three on," she said. "I think that's not insignificant."
Note that:
[The radiologist] told state officials that more data was needed to know whether ultrasound tests actually did a better job detecting tumors in breasts with high density. Ultrasounds typically cost patients more than a mammogram (particularly if their insurance has a high deductible), require skilled technologists and take longer to perform than a mammogram. .... [S]he called [the bill] a case of "putting the cart before the horse," [but that] the law presented a "golden opportunity."
The radiologist’s study has been accepted by publication in The Breast Journal.
Discussion
- The radiologist commented that the finding of 3 additional cases of breast cancer per 1000 through the added ultrasound procedure - beyond the 4 or 5 per 1000 found through previous mammograms - was "not insignificant." Statistically speaking, what do you think she meant by that? Do you consider the phrase "not insignificant" equivalent to the term "significant," in a statistical context?
- Suppose that her finding was statistically significant. Do you think that it was, in a real-life sense, significant enough to justify the costs of an additional ultrasound screening, in time and/or money to a patient, to her insurer, or to a health facility?
- Do you think that CT was "putting the cart before the horse"?
Submitted by Margaret Cibes
The problems with meta-analyses
I had written a more mathematical blog entry in May, 2009 (referenced in CN 59), denoting the logical and mathematical/statistical problems with meta-analyses, but since that time many more meta-analyses have been published, and the public has discussed these results as if they were clinical fact. It is important to understand that the results of a meta-analysis should be presented only as a hypothetical clinical result, to be tested forwards in a properly designed clinical format, and not accepted as proven fact (such as the recent suggestion that women who ingest calcium supplements increase their risk of heart disease). In brief, a meta-analysis collects several studies of the same problem, none of which reaches clinical or statistical significance, in the hopes that the sum can be greater than its parts, and that combining non-significant studies can reach a significant result!
Some readily understandable problems with meta-analyses:
- You are never told which studies the author rejects as not being acceptable for his/her meta-analysis, so you cannot form your own opinion as to the validity of rejecting those particular studies.
- The problem of the Simpson Paradox, or the Yule-Simpson Effect: sometimes all the included studies point in one direction as being clinically significant, but the meta-analysis points in exactly the opposite direction. Numerous illustrations of the paradox have been discussed over the years in Chance News; this post from 2004 demonstrated different ways of calculating Derek Jeter's batting average, with differing results, using the same data in each case.
- There are two different statistical models or assumptions by which the analyzer combines the effects of the individual studies: the fixed effects model and the random effects model. Each model makes different assumptions about the underlying statistical distribution of observed data, so each calculation produces different results.
- There are two different methods for measuring the effect of the clinical intervention: standardized mean difference or correlation. Each method produces a different end result.
- If we look at #3 and #4, we see immediately that there are four possible combinations of analyses, leadeing to four different conclusions for the same set of studies. No one paper shows all four combinations and all four possible results.
- Finally, the choice of what constitutes a "significant' effect in any of the included studies is purely arbitrary. When this question was studied by clinical psychologists, no two analytical scientists reached the same conclusions of what was significant in all the included studies.
We therefore see that the result of any meta-analysis is largely dependent on the analyzer, and the reader never has enough data to redo the analysis, so the results have to be taken on faith, which is hardly a scientific result.
"There are three kinds of lies: Lies, Damn Lies, and Statistics" --Mark Twain
Submitted by Robin Motz
The case of Tamiflu
New questions raised about Tamiflu’s effectiveness
by Andrew Pollack, Prescriptions blog, New York Times, 17 January 2012
This recent news story provides an example of the first concern raised above: the results of a meta-analysis can depend critically on which studies are included. According to claims by its manufacturer, Tamiflu both reduces complications from the flu and helps to prevents transmission. A 2003 meta-analysis of 10 clinical trials appeared to support the first claim, and health agencies have accumulated stocks of Tamiflu for use during a flu pandemic, in hopes that many hospitalizations could be avoided. However, it was later pointed out that only two of these trials had been independently published. In 2009, an analysis focusing only on the published studies did not find evidence that Tamiflu reduced complications.
Now a new study by the Cochrane Collaboration, has raised even more questions. It noted that data on 60 percent of the patients in the clinical trials of Tamiflu had never been formally published. Including the unpublished data in their analysis, the investigators concluded that Tamiflu did not reduce hospitalizations. Moreover, the unpublished trials include more reports of side effects than the published ones. See also this BMJ news release, which details some of the difficulties the Cochrane group has encountered in its efforts to obtain data from Roche, the manufacturer of Tamiflu.
Submitted by Bill Peterson
Larry Summers on statistics
What you (really) need to know
by Lawrence H. Summers, New York Times, 22 January 2012.
Nick Horton sent this reference to the Isolated Statisiticians list, along with the following excerpt (Summers' sixth point) on the value of statistics:
Courses of study will place much more emphasis on the analysis of data. Gen. George Marshall famously told a Princeton commencement audience that it was impossible to think seriously about the future of postwar Europe without giving close attention to Thucydides on the Peloponnesian War. Of course, we’ll always learn from history. But the capacity for analysis beyond simple reflection has greatly increased (consider Gen. David Petraeus’s reliance on social science in preparing the army’s counterinsurgency manual).
As the “Moneyball” story aptly displays in the world of baseball, the marshalling of data to test presumptions and locate paths to success is transforming almost every aspect of human life. It is not possible to make judgments about one’s own medical care without some understanding of probability, and certainly the financial crisis speaks to the consequences of the failure to appreciate “black swan events” and their significance. In an earlier era, when many people were involved in surveying land, it made sense to require that almost every student entering a top college know something of trigonometry. Today, a basic grounding in probability statistics and decision analysis makes far more sense.
Statistics: theory vs. practice
The 2009 edition of a very reputable introductory statistics text, otherwise full of interesting questions and explanations based on real data, contains the following excerpt:
Is the form of the scatterplot straight enough that a linear relationship makes sense? Sure, you can calculate a correlation coefficient for any pair of variables. But correlation measures the strength only of the linear association, and will be misleading if the relationship is not linear.
Discussion
- Refer to the formula for a correlation coefficient as the sum of the products of the z-scores of corresponding pairs of values, all divided by (n-1). Theoretically/mathematically, one cannot calculate a correlation coefficient for any pair of variables. Can you think of an example of a data set with two variables for which the correlation coefficient does not exist?
- Consider data pairs in a real-life, not a theoretical, setting. Explain why the author’s categorical statement about the existence of correlation coefficients is probably more accurate than not, at least in a real-life setting.
Submitted by Margaret Cibes
Marilyn's correction on the drug-testing problem
Ask Marilyn: Did Marilyn make a mistake on drug testing?
by Marilyn vos Savant, Parade, 22 January 2012
In a company with 400 employees, 25% are randomly selected every three months for drug testing. What is the chance that a particular employee is selected (at least once) during the year? As discussed in the previous edition of Chance News, Marilyn misinterpreted this question in her first response, and simply asserted that the chance of being selected in any particular quarter remains 25% (this was already implicit in the original question). The correct answer to the question posed, as explained by several readers, is about 68%, which can be calculated as 1 minus the probability of not being selected. In the present column Marilyn provides her version of the correct solution:
The reasoning works this way: Of the 400 names, 25 percent (100) are selected in the first quarter. Assume “perfect” randomization for the purpose of calculation: Of the 300 that weren’t chosen, 25 percent (75) would be selected in the second quarter. Of the 225 still-unchosen names, 25 percent (about 56) would be selected in the third. And of the 169 remaining unchosen names, 25 percent (about 42) would be selected in the fourth.
So a total of 273 different people (100 + 75 + 56 + 42 = 273) will have been selected—about 68 percent of all the employees. (Many names will have been chosen more than once, so 400 tests are still administered.)
Marilyn's approach amounts to using so-called "natural frequencies" to avoid all the fractions. The corresponding probability calculation would be
<math>.25+(.75)(.25)+(.75^2)(.25)+(.75^3)(.25) = .6836</math>
Gerd Gigerenzer, in numerous publications over the years, has advocated natural frequencies as a more transparent way to present probability arguments for the lay person. See Steven Strogatz's 2010 article Chances are (from his excellent Elements of Math series for the New York Times), where he discusses Gigenzer's book Calculated Risks. One of the examples discussed there uses the natural frequency approach to illuminate the false positive problem in the context of breast cancer screening.
Discussion
- Do you find that Marilyn's presentation clarifies the solution? What if you apply the natural frequency approach to the complementary event?
Submitted by Bill Peterson
Berlin Numeracy Test
Measuring risk literacy: The Berlin Numeracy Test
by Edward T. Cokely et al., Judgment and Decision Making, January 2012
This 23-page paper introduces a new instrument that purports to assess statistical literacy more quickly, yet effectively, than the most common ones in current use. The authors administered the test to folks from many countries, among diverse well educated groups, with a focus on those who are charged with extremely important decisions, such as health professionals. They drew questions from other commonly used tests and developed some of their own. The paper includes lots of statistics about the authors’ results, as well as comparisons with other traditional tests.
The Berlin Numeracy Test was found to be the strongest predictor of comprehension of everyday risks…. The Berlin Numeracy Test typically takes about three minutes to complete and is available in multiple languages and formats…. The online forum[1] also provides interactive content for public outreach and education…..
Here are some questions that are included in the paper:
1. Out of 1,000 people in a small town 500 are members of a choir. Out of these 500 members in the choir 100 are men. Out of the 500 inhabitants that are not in the choir 300 are men. What is the probability that a randomly drawn man is a member of the choir? Please indicate the probability in percent.
2a. Imagine we are throwing a five-sided die 50 times. On average, out of these 50 throws how many times would this five-sided die show an odd number (1, 3 or 5)? ______ out of 50 throws.
2b. Imagine we are throwing a loaded die (6 sides). The probability that the die shows a 6 is twice as high as the probability of each of the other numbers. On average, out of these 70 throws how many times would the die show the number 6? ________out of 70 throws.
3. In a forest 20% of mushrooms are red, 50% brown and 30% white. A red mushroom is poisonous with a probability of 20%. A mushroom that is not red is poisonous with a probability of 5%. What is the probability that a poisonous mushroom in the forest is red? ________
Judgment and Decision Making is a free online journal.
Discussion
- The authors state, “Correct answers are as follows: 1 = 25; 2a = 30; 2b = 20; 4 = 50.” Do you agree with all of these solutions?
- To get the authors’ answer to question 2a, we must assume that each side of the die is equally probable. However, a five-sided die is not one of the five Platonic solids (tetrahedron, cube, octahedron, dodecahedron, icosahedron). Could you construct a five-sided die with equally probable sides?
Submitted by Margaret Cibes
Facebook IPO purchasers may face paradox
Facebook and the St. Petersburg Paradox
by Jason Zweig, The Wall Street Journal, February 4, 2012
The author discusses the potential relevancy of the St. Petersburg paradox to investment decisions, in particular to a decision about purchasing Facebook stock at its initial public offering (IPO).
[T]he paradox works like this: I will toss a coin until it comes up heads, at which point you get paid and the game ends. You get 1 dollar if the coin comes up heads on the first toss, 2 dollars if the coin comes up heads on the second, 4 dollars if it is heads on the third, 8 dollars on the fourth and so on. Your prospective payoff doubles with each successive flip until the coin finally lands on heads and the game is over.
The author feels that the paradox explains why growth stocks become overvalued so easily. While the payoff for the coin-tossing game is theoretically infinite, researchers have found that people will only pay about 20 dollars to participate.
Facebook stock may be appealing because its users may feel as connected to the company as to the services it provides. However, like a St. Petersburg coin:
The potential payoffs are enormous, although not infinite – and the game might peter out all too soon. …. Just as the coin-flipping game in the St. Petersburg Paradox can end on any toss, even the fastest-growing company's upward trajectory can flatten in a flash. …. "The valuation is so high today that the upside potential is limited," [says a finance professor].
Here are excerpts from some blogger observations:
- “The company is a controlled company, it doesn’t actually have to have an independent board, or a nominating or a compensation committee. Mr. Zuckerberg controls the coin being flipped.”
- “[T]he answer has to do with depth of your pocket book.”
There are several other blogs whose authors claim to demonstrate detailed calculations of the expected values of the St. Petersburg coin-flip game, as they relate to the 20-dollar figure, and might be of interest to readers wishing to analyze the bloggers' reasoning for correctness.
Submitted by Margaret Cibes
Online matchmaking
The dubious science of online dating
by Eli J. FIinkel and Benjamin R. Karney, New York Times, 11 February 2012
The authors ask "[C]an a mathematical formula really identify pairs of singles who are especially likely to have a successful romantic relationship?" They believe not. In the article we read:
According to a 2008 meta-analysis of 313 studies, similarity on personality traits and attitudes had no effect on relationship well-being in established relationships. In addition, a 2010 study of more than 23,000 married couples showed that similarity on the major dimensions of personality (e.g., neuroticism, impulsivity, extroversion) accounted for a mere 0.5 percent of how satisfied spouses were with their marriages — leaving the other 99.5 percent to other factors.
None of this suggests that online dating is any worse a method of meeting potential romantic partners than meeting in a bar or on the subway. But it’s no better either.
Submitted by Paul Alper
NAS program on science communication
Margaret Cibes wrote to call attention to an upcoming conference The Science of Science Communication, which takes place in May. It is sponsored by the National Academy of Science in their Sackler Colloquium series. This year's keynote address will be given by Daniel Kahneman. As Margaret notes, many of us have drawn classroom examples from the celebrated Kahneman-Tversky research on judgment under uncertainty.
Kahneman's latest book is Thinking, Fast and Slow. It was reviewed last year in the New York Times (see Two brains running, by Jim Holt, 21 November 2011). Among the examples discussed there is a Kahneman and Tversky's classic, the "Linda problem."
Some rules for science journalism
What if there were rules for science journalism?
by Fiona Fox, Slate, 11 December 2011
On the subject of science communication, Slate reprinted this article from the New Scientist. It is subtitled, "No false balance, no miracle cures, no opaque statistics …" It cites the alleged link between MMR vaccine and autism as a prime example of what can go wrong when the press is not sufficiently skeptical in medical reporting (see discussion of this story in CN 70 and earlier links there on the long history of debunking this story).
Reproduced below are some of the article's recommendations for reporting on medical studies:
- include the sample size and explain when it may be too small to draw general conclusions
- present changes in risk in absolute terms as well as percentages
- provide a realistic time frame for the work's translation into a treatment or cure
- don't obsess over "balance" in cases where the preponderance of scientific evidence is on one side (e.g. climate research)
- hold back on reporting extraordinary claims until there is extraordinary evidence
- follow up stories with equally significant coverage if claims are later refuted
These will of course be familiar to many statisticians. Indeed, one of the comments on the Slate story directs readers to the very useful website HealthNewsReview.org website. Another comment notes the need for checking statistical claims in all stories, not just those on medicine. In that vein, see also the recent Wall Street Journal Number's Guy commentary on numerical literacy in the previous edition of Chance News.