Chance News 72
March 11, 2011 to April 30, 2011
J. Laurie Snell, 1925-2011
Laurie Snell, the founder and long-time editor of Chance News, died on March 19. He was 86 years old. Laurie taught at Dartmouth College for 42 years until his retirement in 1995. He continued to edit the newsletter for another 10 years, and then oversaw its transformation into a Wiki, to which he remained a primary contributor.
Laurie had a truly remarkable mathematical career. He completed his doctoral research on martingale theory under Joseph Doob. One of his key constructions, the “Snell envelope,” continues to find important applications in mathematical finance. His collaboration with John Kemeny at Dartmouth led to the classic treatises Finite Markov Chains and Denumerable Markov Chains (the latter also with Anthony Knapp). With Kemeny and Gerald Thompson, Laurie co-authored the ground-breaking Introduction to Finite Mathematics textbook. In the years following its publication, courses of that name became standard offerings across the country.
Laurie was a great believer in the value of the Internet for sharing scholarship and teaching materials. His Introduction to Probability textbook with Charles Grinstead, and his monograph Random Walks and Electrical Networks with Peter Doyle, and are both available online. Peter has also undertaken to keep the original Introduction to Finite Mathematics materials available. Resources from the Chance Project, which under Laurie's direction grew to include a lecture series, faculty workshops, and a variety of teaching aids, are archived at the Chance Database at Dartmouth.
Laurie was an ever-generous colleague, who had a gift of making everyone feel at ease in his presence. He was genuinely interested in others, and especially supportive of junior colleagues. He was a lover of music and the outdoors, and visitors to Dartmouth were invited to join in concert events, hikes in the New Hampshire mountains, and superb meals, often accompanied by his gracious wife Joan. To those who knew him and worked with him, he provided a wonderful model of all the best things about an academic life.
He will be greatly missed.
Bill Peterson
Quotations
"Self-selected samples are not much more informative than a list of correct predictions by a psychic."
Submitted by Paul Alper
"[S]tatistical analysis is being used, and not always to your benefit, by everyone from your cable company to your real estate broker. Consider this your chance to fight back."
Submitted by Bill Peterson
"But all evolutionary biologists know that variation itself is nature's only irreducible essence. Variation is the hard reality, not a set of imperfect measures for a central tendency. Means and medians are the abstractions."
Submitted by Bill Peterson
“That doesn’t necessarily mean that the relationship is meaningless. Gas prices are competing against a whole host of other factors that affect elections. With a small number of data points . . . it will always be challenging to detect any signal through the noise. Those who study presidential elections need to remember that absence of evidence isn’t necessarily evidence of absence.”
The New York Times, 2 March 2011
Submitted by Margaret Cibes
Forsooth
"Persons with higher numeracy rely more on the numerical information depicted in the graph, whereas persons with lower numeracy seem to be confused when they are guided towards these numbers." [abstract]
Risk communication with pictographs, Hess et al., Judgment and Decision Making, April 2011
Submitted by Margaret Cibes
P-value revealed
The typical elementary statistics textbook is dry as dust and mostly useful as a doorstop. Andrew Vickers’ What is a p-value anyway? 34 Stories To Help You Actually Understand Statistics, consists of only 210 pages and is too thin to stop many doors but is extremely amusing, full of insight and good advice. His aim was to “write something that (a) focused on how to understand statistics, (b) avoided formulas and (c) was fun, at least in places.” And, that “is how he came with the idea of stories.” The 34 chapters are stories which are intended to illustrate statistical concepts, but are “short and fun to read.” Some of his stories may be found on Medscape.com and can be viewed once you sign on to Medscape (at no cost).
Despite the title, p-value does not appear until Chapter (i.e., Story) 13, page 55, although the related concept, confidence interval, is first mentioned on page 25. Here is what he has to say about the inappropriate use of confidence intervals:
You might say that the indiscriminant use of confidence intervals in scientific papers is because the authors don’t have a firm idea of what it is that they want to find out. And you might be right--I couldn’t possibly comment.
Likewise, when it comes to p-value and the mindless use of stats packages:
[I]t is all too easy to generate endless lists of p-values using statistical software, regardless of whether any of them address a question you actually want to answer.
As good as his book is, the reader will probably need some auxiliary help, perhaps by way of an organic doorstopper.
Discussion
1. Vickers has not yet entered into the controversy regarding Bem’s ESP article which rests more or less solely on a p-value of less than .05. However, on page 172, Vickers writes
On the other hand, there is an idea that all cancers are caused by a parasitic infection and can be cured by a special “zapper”. (You can’t make this stuff up) If you showed me a medical study showing that these zappers cured cancer with a p-value of .04, I’d probably say something like, “Well, that is surprising, but it is a ridiculous hypothesis, there is no reason to believe it is true other than this one measly p-value. So thanks but no thanks, I am not going to believe in this hypothesis for now.”
Instead of a “measly” p-value of .04, suppose the p-value were far, far smaller such as 10^-35 which has been alleged in previous ESP studies. What might his reaction now be?
2. On page 208 he criticizes the use of weasel words such as “may,” “might,” and “could” which “are often found in the conclusion of scientific studies.” He speculates that “The reason words like ‘may,’ ‘might’ and ‘could’ are so popular is that it absolves the author from any responsibility whatsoever.” He then employs the following satirical comment to justify his criticism:
Students may learn more statistics from reading What is p-value anyway? than from any competing statistics textbook.
Do a possibly non-random sample of recently published articles in any field to determine the prevalence of those weasel words.
3. Vickers points out that “missing data is a big problem in medical research.” Imputing the value of the missing data, as might be imagined, is tricky and fraught with difficulties. One of his contributions was “to reduce the rate of missing data in the first place” by telephoning “patients at home and ask[ing] them just two question in place of a long questionnaire. In this way, we reduced the rate of missing data in a trial from 25% to 6%, which made the use of complex missing data rather redundant.” Comment on the ease of doing such pre-trial contact in this age of privacy and security. Comment on the ease of doing a post-trial contact in this age of privacy and security.
4. His definition of p-value is the standard “The p-value is the probability that the data would be at least as extreme as those observed if the null hypothesis were true.” Bayesians are unhappy with the phrase “at least as extreme” as reflected in the famous quote of Harold Jeffreys: “What the use of P[-value] implies, therefore, is that a hypothesis that may be true may be rejected because it has not predicted observable results that have not occurred.” Another famous related criticism of the use of p-value may be found via the so called optional stopping problem whereby the p-value is not unique. For some other shortcomings and possibilities for misinterpreting of p-value, see this. If these criticisms are valid, why then is p-value so ubiquitous?
5. On page 204 Vickers writes,
I generally take the position “never attribute to conspiracy what you can attribute to a simple screw-up.” Nevertheless, when you see bad statistics, it is worth wondering who stands to gain.
On the other hand, read (A) White Coat Black Hat: Adventures on the Dark Side of Medicine by Carl Elliott or (B) Bad Science: Quacks, Hacks and Big Pharma Flacks by Ben Goldacre to see just how prevalent they claim conspiracies are in the medical world.
6. On page 148, Vickers looks askance at “what is perhaps the most typical approach to statistics:”
• Load up the data into the statistics software.
• Press a few buttons.
• Cut and paste the results in a word processing document.
• Look at the p-value. If p is less than .05, that is a good thing. If p >= .05, your study was a failure and probably isn’t worth sending to a scientific journal.
Why is he so scornful of this approach?
7. On page 143, Vickers invokes what he christens “J-Com’s Law in honor of the worst typing mistake in history:”
Many of the research papers you read will be wrong not as a result of scientific flaws, poor design or inappropriate statistics, but because of typing errors.
Go to this web site to see what happened to Mizuho Securities Co. and the Tokyo Stock Exchange in December, 2005 due to a typing error.
8. He puts forward on page 193 a “rule of thumb: if you have the whole population, rather than a sample, don’t report confidence intervals and p-values.” If “we have all the data that we could get, that is, the whole population,” then “[a]ccordingly, we say these things with confidence and leave out the confidence interval.” Give several examples in which the investigator might have the entire population.
Submitted by Paul Alper
Pi day probability puzzle
Numberplay: Pi in the sky
by Pradeep Mutalik, New York Times Wordplay Blog, 14 March 2011
Among the three puzzles posed for Pi Day (3/14) is this:
2. Notice that in the decimal expansion of pi, zero is the last digit to appear, and does not appear till the 32nd decimal place. This seems to be a long time for the last digit to appear. What is the expected place for the last digit to appear in a truly random series of digits, as the decimal expansion of transcendental numbers like pi is known to be?
As posed, this becomes an application of the Coupon Collector's problem. However, it is still unknown whether π is a normal number, even though mathematicians suspect that this is true. For a class activity on empirical digit frequencies, see How normal is pi?. The question of whether the digits are "truly random" is even more subtle; for discussion see this article by Stan Wagon.
Submitted by Bill Peterson
Redefining pi in 2011
Huffington Post chipped in to the March 2011 pi celebrations with an article: “Conservative Pie: Republicans Introduce Legislation Redefining Pi as Exactly 3”. The article is a spoof, but one wonders how actual many attempts there have been to redefine pi since the Indiana General Assembly's deliberations in 1897 ("pi = 3.2").
See a news story about the present article in Live Science: “Simplifying Pi?: Article a Hoax, But Hits Close to Home”.
Submitted by Margaret Cibes
Coping with bad medical news
Matthew Hayat recommended the following article on the Isolated Statisticians list.
After a diagnosis, wishing for a magic number
by Peter B. Bach, M.D., New York Times Well Blog, 21 March 2011
Contrasts the optimistic point of view expressed in Steven Jay Gould's classic The median isn't the message with a more sobering essay, Letting go, by Atul Gawande in the New Yorker last year (8 August 2010).
Submitted by Bill Peterson
A nonsignificant result won't protect you in a court of law
Supreme Court Rules Against Zicam Maker, Adam Liptak, The New York Times, March 22, 2011.
Matrixx Initiaves, Inc., et al. v. Siracusano et al., U.S. Supreme Court, 2011.
Investors in a company called Matrixx Initiatives got angry when they weren't told about side effect reports for that company's biggest product, Zicam.
The case involved Zicam, a nasal spray and gel made by Matrixx Initiatives and sold as a homeopathic medicine. From 1999 to 2004, the plaintiffs said, the company received reports that the products might have caused some users to lose their sense of smell, a condition called anosmia. Matrixx did not disclose the reports and in 2003, the company said it was “poised for growth” and had “very strong momentum” though, by the plaintiffs’ calculations, Zicam accounted for about 70 percent of its sales.
The company defended itself by pointing out that
it should not have been required to disclose small numbers of unreliable reports, which were the only ones available in 2004. They added that the company should face liability for securities fraud only if the reports had been collectively statistically significant.
The Supreme Court rules against Matrixx. One comment by Sonia Sotomayor was quite interesting.
Given that medical professionals and regulators act on the basis of evidence of causation that is not statistically significant, it stands to reason that in certain cases reasonable investors would as well.”
She goes on to say that just any old set of adverse reports wouldn't meet this standard, but that the courts must look at
the source, content and context of the reports
Additional commentary on the Supreme Court Decision can be found by Carl Bialik at the Wall Street Journal and by Scot Silverstein on the Health Care Renewal blog.
Submitted by Steve Simon
Questions
1. If statistical significance is not a standard for establishing causation, what would be the alternate standard?
2. How does the responsibility of Matrixx to its investors differ from its responsibility to its customers and to FDA?
3. What action should a company take to a small number of reports of serious side effects when those reports fail to meet the criteria of statistical significance?
More on “A nonsignificant result”
“Matrixx Initiaves, Inc., et al. v. Siracusano et al.”
Here are a few more direct quotations for discussion (not necessarily criticism), from the U.S. Supreme Court’s Matrixx opinion described in the preceding piece:
Statistically significant data are not always available. For example, when an adverse event is subtle or rare, “an inability to obtain a data set of appropriate quality or quantity may preclude a finding of statistical significance.” Moreover, ethical considerations may prohibit researchers from conducting randomized clinical trials to confirm a suspected causal link for the purpose of obtaining statistically significant data. A lack of statistically significant data does not mean that medical experts have no reliable basis for inferring a causal link between a drug and adverse events.
The FDA similarly does not limit the evidence it considers for purposes of assessing causation and taking regulatory action to statistically significant data. In assessing the safety risk posed by a product, the FDA considers factors such as “strength of the association,” “temporal relationship of product use and the event,” “consistency of findings across available data sources,” “evidence of a dose-response for the effect,” “biologic plausibility,” “seriousness of the event relative to the disease being treated,”“potential to mitigate the risk in the population,” “feasibility of further study using observational or controlled clinical study designs,” and “degree of benefit the product provides, including availability of other therapies.”
[Footnote] A study that is statistically significant has results that are unlikely to be the result of random error.” To test for significance, a researcher develops a “null hypothesis”—e.g., the assertion that there is no relationship between Zicam use and anosmia. The researcher then calculates the probability of obtaining the observed data (or more extreme data) if the null hypothesis is true (called the p-value). Small p-values are evidence that the null hypothesis is incorrect. Finally, the researcher compares the p-value to a preselected value called the significance level. If the p-value is below the preselected value, the difference is deemed “significant.”
Submitted by Margaret Cibes
Data visualization goes mainstream
When the data struts its stuff
by Natasha Singer, New York Times, 3 April 2011
The article quotes Hans Roesling, famous for his Gapminder animated data presentations, as saying "Statistics is now the sexiest subject around."
What will happen as such tools become more widely commercialized? Here is an example from the article,
http://graphics8.nytimes.com/images/2011/04/03/business/STREAM-3/STREAM-3-popup.jpg
{kind=link}
Readers are probably accustomed to seeing web sites with keyword clouds that represent word frequencies by varying character size. The above graphic tracks Twitter traffic during an MTV awards show, with the size of celebrities' photos representing how often they appeared in tweets.
On a what was intended to be a more serious note, this following specimen of chart junk appeared in a Times Op/Ed piece from February, Inside the Muslim (journalist’s) mind
http://community.middlebury.edu/~wpeterso/Chance_News/images/CN72_Threats.png
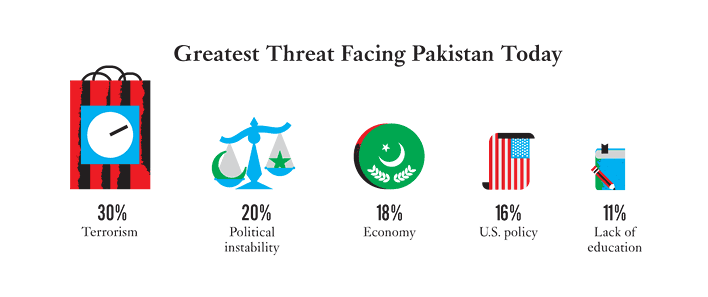{kind=link}
For the full version of the graphic, click here
{kind=link}
Submitted by Bill Peterson
Gas prices vs. presidential support
“Risks to Obama in Oil Price Instability”
by Nate Silver, Five Thirty Eight: Nate Silver’s Political Calculus
The New York Times, March 2, 2011
Silver’s ongoing political blog contains lots of raw data, sources, and political/statistical analysis. This particular blog is timely, in view of the recent rise in oil/gas prices. Silver asks whether
“higher gas prices, by themselves, tend to significantly damage the president’s standing.” He concludes, “[T]here’s not a lot of evidence that oil prices are all that important.”
He provides the following table:
http://www.538host.com/gaspres0.png
{kind=link}
He states, “Over all, the relationship goes in the direction that you might expect — higher gas prices mean a poorer performance for the incumbent party — but it is fairly weak statistically.”
Two charts show the margin of victory of an incumbent party plotted against retail gas prices in 2011 dollars:
(1) for all presidential elections since 1948[1], R^2 = 0.15.
(2) for only presidential elections since 1948 in which an incumbent president was a candidate[2], R^2 = 0.13.
![[1]](http://www.538host.com/gaspres3.png){kind=link}
![[2]](http://www.538host.com/gaspres4.png){kind=link}
Discussion
Refer to the Gas and Margin columns in the table.
Silver states, “[T]he relationship between the two variables falls short of being statistically significant.”
1. The margin of victory declines by about how many percentage points for each dollar increase in gas price?
2. What statistic would you test in order to assess the level of significance of the relationship between the two variables? What is the value of that statistic?
3. Would you consider that statistic statistically significant? Why or why not?
Submitted by Margaret Cibes
U.S. sovereign debt downgrade
“Rating On United States of America Affirmed; Outlook Revised To Negative”
Standard & Poor's, April 18, 2011
The U.S. fiscal situation has been getting increasing attention because of the counry's sizable and growing debt-to-GDP ratio. Many in financial markets worry that while currently manageable, the debt's increasing size, driven by a large and persistent budgetary deficit, will eventually cause a crisis for the U.S. in global bond markets.
Today a major credit rating agency downgraded, for the first time, the outlook for the U.S.'s creditworthiness. While leaving the U.S. at its highest overall rating, S&P said that it was revising the country's credit outlook to "Negative", signaling the potential for a future downgrade to a lower credit rating. This would have serious implications for the interest rates the U.S. might have to pay to sell its debt. In the short term, there is the potential that S&P's downgrade could cause credit worsening, as bond buyers required higher interest rates, thus causing a near-term deterioration in U.S. finances, and thereby hastening a credit downgrade by S&P.
How like is such a future downgrade? S&P said in its release today that there is a " one-in-three likelihood that we could lower our long-term rating on the U.S. within two years".
Discussion
Consider the probability statement made by S&P about the U.S.'s credit rating.
- Given that S&P is making a statement about its own future actions, actions driven in part by how markets respond to its action today, how meaningful is this probability assessment?
- How might you create a more credible assessment of the risk of a future downgrade?
- Should credit ratings agencies deal in probabilities with respect to their own future actions?
Submitted by Paul Kedrosky
Cheap shots
This 2009 compilation is a rich source of descriptive data charts – some good, some bad. A new copy only costs about $11.
Submitted by Margaret Cibes based on an ISOSTAT posting